1) GMM-UBM model

GMM-UBM模型
2) Gaussian mixture model-universal background model(GMM-UBM)
Gauss混合模型-通用背景模型(GMM-UBM)
3) sub-band GMM-UBM
子带GMM-UBM
1.
And because the background noise of the broadcast speech is not the simply full-band Gaussian white noise,a language recognition system is built based on sub-band GMM-UBM model and subsystems structure by using ne.
提出了一种基于概率统计模型的与语言内容无关的语种识别方法,它不需要掌握各语种的专业语言学知识就可以实现几十种语言的语种识别;并针对广播语音噪声干扰大的特点,采用GMM-UBM模型作为语种模型,提高了系统的噪声鲁棒性;由于广播语音的背景噪声不是简单的全频带加性白噪声,因此本文构建了一种基于子带GMM-UBM模型的多子系统结构的语种识别系统,后端采用神经网络进行系统级融合。
5) Gaussian mixture model (GMM)
高斯混合模型(GMM)
6) Gaussian mixture model(GMM)
高斯混合模型(GMM)
1.
Support vector machines(SVM) and Gaussian mixture model(GMM) are widely applied to the speaker verification,but they both have the disadvantages.
阐述高斯混合模型(GMM)和支持向量机(SVM)建立的基本原理,分别指出高斯混合模型和支持向量机在实际应用中的不足之处,并针对两种模型的特点,提出将GMM模型的输出机制引入到SVM模型中,以便于调整支持向量机(SVM)模型的概率输出,并建立SVM-GMM混合模型。
补充资料:AutoCad 教你绘制三爪卡盘模型,借用四视图来建模型
小弟写教程纯粹表达的是建模思路,供初学者参考.任何物体的建摸都需要思路,只有思路多,模型也就水到渠成.ok废话就不说了.建议使用1024X768分辨率
开始
先看下最终效果

第一步,如图所示将窗口分为四个视图

第二步,依次选择每个窗口,在分别输入各自己的视图

第三步,建立ucs重新建立世界坐标体系,捕捉三点来确定各自的ucs如图
第四步,初步大致建立基本模型.可以在主视图建立两个不同的圆,在用ext拉升,在用差集运算.如图:
第五步:关键一步,在此的我思路是.先画出卡爪的基本投影,在把他进行面域,在进行拉升高度分别是10,20,30曾t形状.如图:
第六步:画出螺栓的初步形状.如图
第七步:利用ext拉升圆,在拉升内六边形.注意拉升六边行时方向与拉升圆的方向是相反的.
之后在利用差集运算
第八步:将所得内螺栓模型分别复制到卡爪上,在利用三个视图调到与卡爪的中心对称.效果如图红色的是螺栓,最后是差集
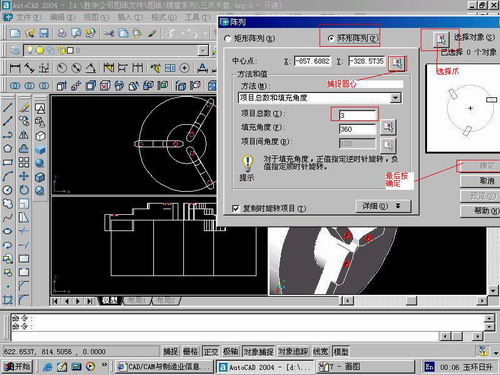
第九步:阵列
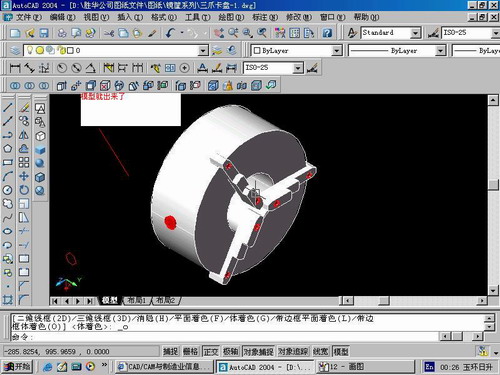
第10步.模型就完成了
来一张利用矢量处理的图片

说明:补充资料仅用于学习参考,请勿用于其它任何用途。
参考词条