1) sinusoidal plus noise model

正弦加噪声模型
1.
A voice conversion approach with a sinusoidal plus noise model is introduced and a parametric conversion algorithm based on phoneme segments is discussed in this paper.
提出一种基于正弦加噪声模型的说话人转换方法,着重讨论通过修改音素段内的声学参数实现说话人的转换。
2) Sinusoidal signal plus Gaussian noise
正弦信号加高斯噪声
3) Additive noise model
加性噪声模型
4) sinusoidal model
正弦模型
1.
An audio compression algorithm based on sinusoidal model;
一种基于正弦模型的音频压缩算法
2.
Research on Linear Predictive Speech Coding Based on Sinusoidal Model at Low-Bit-Rates;
基于正弦模型的线性预测低速率语音编码算法研究
3.
Energy-spectrum entropy and subharmonic-harmonic rate methods were used to analyze speech based on speech sinusoidal model.
基于语音正弦模型,采用能量谱熵和子谐波谐波比率方法进行语音分析。
6) noise model
噪声模型
1.
Analysis of noise model of multiplier in sensor circuit;
传感器电路中乘法器噪声模型分析
2.
Study on noise models algorithms and matrix descriptions for integrated circuits;
集成电路噪声模型算法及其矩阵表达
3.
The original noise model of a two port network is given.
从放大器实际存在的时域原始噪声模型出发,推导出两个时域等效噪声模型,并由此扩展到频域,得到了相对应的几个功率谱噪声模型,从而系统地给出了双口网络噪声模型理论和一系列实用的计算公式。
补充资料:AutoCad 教你绘制三爪卡盘模型,借用四视图来建模型
小弟写教程纯粹表达的是建模思路,供初学者参考.任何物体的建摸都需要思路,只有思路多,模型也就水到渠成.ok废话就不说了.建议使用1024X768分辨率
开始
先看下最终效果

第一步,如图所示将窗口分为四个视图

第二步,依次选择每个窗口,在分别输入各自己的视图

第三步,建立ucs重新建立世界坐标体系,捕捉三点来确定各自的ucs如图
第四步,初步大致建立基本模型.可以在主视图建立两个不同的圆,在用ext拉升,在用差集运算.如图:
第五步:关键一步,在此的我思路是.先画出卡爪的基本投影,在把他进行面域,在进行拉升高度分别是10,20,30曾t形状.如图:
第六步:画出螺栓的初步形状.如图
第七步:利用ext拉升圆,在拉升内六边形.注意拉升六边行时方向与拉升圆的方向是相反的.
之后在利用差集运算
第八步:将所得内螺栓模型分别复制到卡爪上,在利用三个视图调到与卡爪的中心对称.效果如图红色的是螺栓,最后是差集
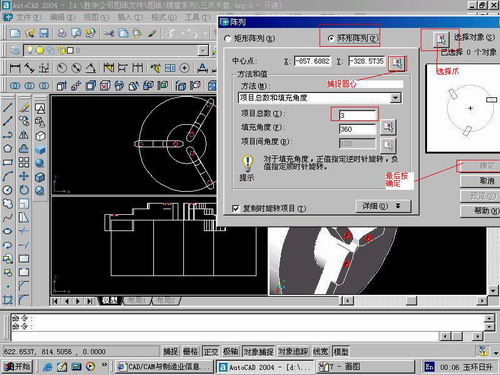
第九步:阵列
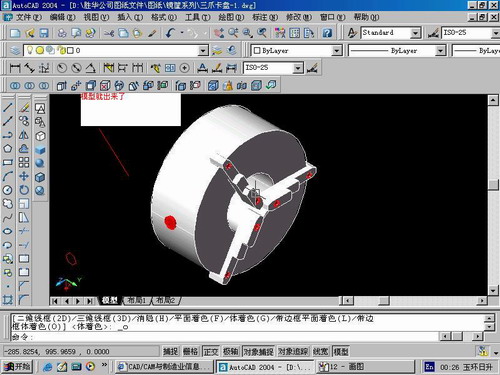
第10步.模型就完成了
来一张利用矢量处理的图片

说明:补充资料仅用于学习参考,请勿用于其它任何用途。
参考词条