1) text mining mode

文本挖掘模型
2) chinese text mining framework
中文文本挖掘模型
3) text data mining model
文本数据挖掘模型
1.
Based on the combination of XML and Web text data mining,Web text data mining model based on XML is put forward which is of certain value in searching important knowledge from abundant Web resources.
本文在分析Web数据挖掘相关理论基础上,深入探讨XML在Web数据挖掘中应用问题,利用XML和Web数据挖掘技术的结合点,提出建立基于XML的Web文本数据挖掘模型,为如何从大量的Web资源中获得有价值的知识提供了一种可行的解决方案。
4) text mining
文本挖掘
1.
Technology maturity of product forecasting based on text mining;
基于文本挖掘技术的产品技术成熟度预测
2.
The applications of ISODATA method in text mining;
ISODATA动态聚类算法在文本挖掘中的应用
3.
Quality estimation of patent based on text mining and its empirical research;
基于文本挖掘技术的专利质量评价与实证研究
5) model of XML-based web text mining
基于XML的Web文本挖掘模型
1.
The definition of XML and web text mining is introduced generally,a model of XML-based web text mining is designed,and the parts of the model is analysed,and finally the characteristics of the model is presented.
介绍了XML的和Web文本挖掘的概念,提出了一种基于XML的Web文本挖掘模型,剖析了该模型的各个组成部分,给出了该模型的特点。
6) mining model
挖掘模型
1.
Design of web mining model based on XML;
基于XML的Web数据挖掘模型的设计
2.
Mining Model for the Insurance Risk Rules Based on Rough Set;
基于粗糙集的保险风险规则挖掘模型
3.
Then it establishes a mining model for the insurance retainment rules based on rough sets.
基于粗糙集基本理论,分析了衡量规则价值的方法,构建了一个基于粗糙集理论的续保规则挖掘模型。
补充资料:AutoCad 教你绘制三爪卡盘模型,借用四视图来建模型
小弟写教程纯粹表达的是建模思路,供初学者参考.任何物体的建摸都需要思路,只有思路多,模型也就水到渠成.ok废话就不说了.建议使用1024X768分辨率
开始
先看下最终效果

第一步,如图所示将窗口分为四个视图

第二步,依次选择每个窗口,在分别输入各自己的视图

第三步,建立ucs重新建立世界坐标体系,捕捉三点来确定各自的ucs如图
第四步,初步大致建立基本模型.可以在主视图建立两个不同的圆,在用ext拉升,在用差集运算.如图:
第五步:关键一步,在此的我思路是.先画出卡爪的基本投影,在把他进行面域,在进行拉升高度分别是10,20,30曾t形状.如图:
第六步:画出螺栓的初步形状.如图
第七步:利用ext拉升圆,在拉升内六边形.注意拉升六边行时方向与拉升圆的方向是相反的.
之后在利用差集运算
第八步:将所得内螺栓模型分别复制到卡爪上,在利用三个视图调到与卡爪的中心对称.效果如图红色的是螺栓,最后是差集
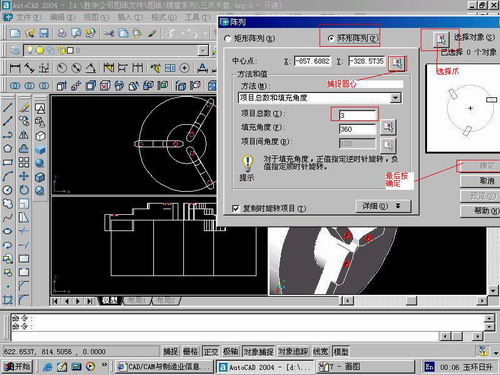
第九步:阵列
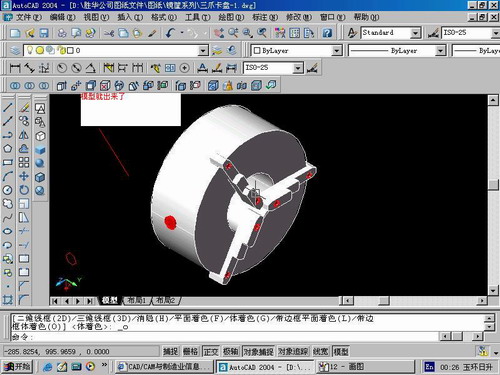
第10步.模型就完成了
来一张利用矢量处理的图片

说明:补充资料仅用于学习参考,请勿用于其它任何用途。
参考词条